combustion.nn¶
Extensions to torch.nn, ranging from fundamental layers
up to larger building blocks.
combustion.nn
Activation Functions¶
-
class
combustion.nn.Swish[source]¶ The swish activation function, defined as
\[f(x) = x \cdot \text{sigmoid}(x) \]Warning
This method is traceable with TorchScript, but is un-scriptable due to the use of
torch.autograd.Functionfor a memory-efficient backward pass. Please export usingtorch.jit.trace()after callingmodule.eval().Initializes internal Module state, shared by both nn.Module and ScriptModule.
-
class
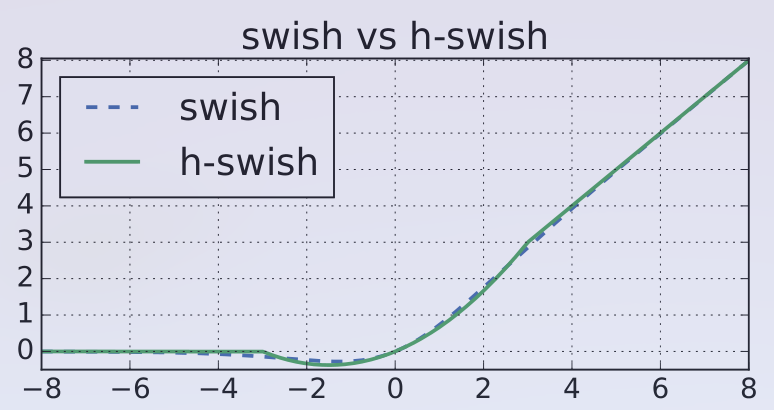
combustion.nn.HardSwish(inplace=False)[source]¶ The hard swish activation function proposed in Searching For MobileNetV3, defined as
\[f(x) = x \cdot \frac{\text{ReLU6}(x + 3)}{6} \]Hard swish approximates the swish activation, but computationally cheaper due to the removal of \(\text{sigmoid}(x)\).
- Parameters
inplace (bool, optional) – Whether or not to perform the operation in place.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
-
class
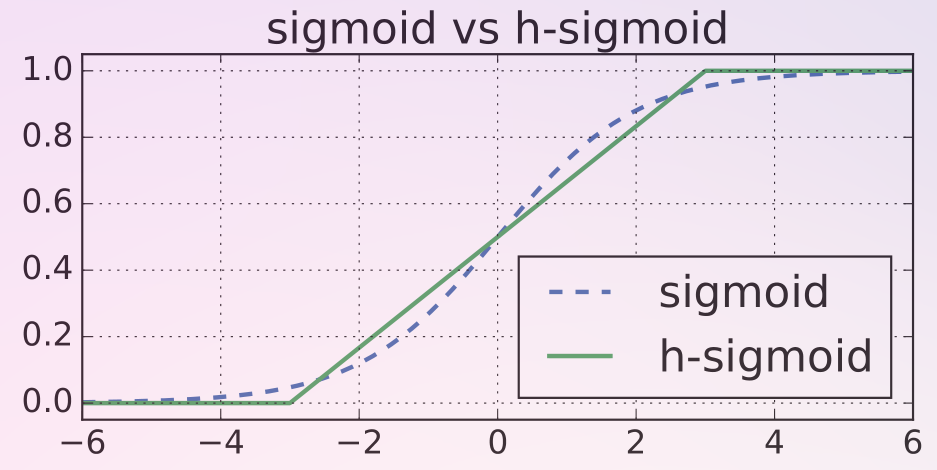
combustion.nn.HardSigmoid(inplace=False)[source]¶ The hard sigmoid activation function, defined as
\[f(x) = \frac{\text{ReLU6}(x + 3)}{6} \]Hard sigmoid is a computationally efficient approximation to the sigmoid activation and is more suitable for quantization.
- Parameters
inplace (bool, optional) – Whether or not to perform the operation in place.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
Convolution Layers¶
-
class
combustion.nn.Bottleneck1d(in_channels, out_channels, kernel_size, bn_depth=None, bn_spatial=None, stride=1, padding=None, dilation=1, repeats=1, groups=1, bias=False, padding_mode='zeros', checkpoint=False)[source]¶ Applies a 1D bottlnecked convolution over an input. Bottlnecked convolutions are detailed in the paper MobileNetV2: Inverted Residuals and Linear Bottlenecks .
Note
Nonlinearities are omitted for low dimensional subspaces as mentioned in section 6 of the paper MobileNetV2: Inverted Residuals and Linear Bottlenecks ,
- Parameters
in_channels (int) – Number of channels in the input image
out_channels (int) – Number of channels produced by the convolution
bn_depth (int) – Bottleneck strength in the channel dimension
bn_spatial (int) – Bottleneck strength in the spatial dimension
stride (int or tuple, optional) – Stride of the convolution. Default: 1
padding (int or tuple, optional) – Zero-padding added to both sides of the input. Default: 0
dilation (int or tuple, optional) – Spacing between kernel elements. Default: 1
repeats (int) – Number of convolutions to perform in the bottlenecked space
groups (int, optional) – Number of blocked connections from input channels to output channels. Default: 1
bias (bool, optional) – If
True, adds a learnable bias to the output. Default:Truepadding_mode (string, optional) –
'zeros','reflect','replicate'or'circular'. Default:'zeros'checkpoint (bool) –
Initializes internal Module state, shared by both nn.Module and ScriptModule.
-
forward(input)¶ - Parameters
input (torch.Tensor) –
- Return type
-
class
combustion.nn.Bottleneck2d(in_channels, out_channels, kernel_size, bn_depth=None, bn_spatial=None, stride=1, padding=None, dilation=1, repeats=1, groups=1, bias=False, padding_mode='zeros', checkpoint=False)[source]¶ Applies a 2D bottlnecked convolution over an input. Bottlnecked convolutions are detailed in the paper MobileNetV2: Inverted Residuals and Linear Bottlenecks .
Note
Nonlinearities are omitted for low dimensional subspaces as mentioned in section 6 of the paper MobileNetV2: Inverted Residuals and Linear Bottlenecks ,
- Parameters
in_channels (int) – Number of channels in the input image
out_channels (int) – Number of channels produced by the convolution
bn_depth (int) – Bottleneck strength in the channel dimension
bn_spatial (int) – Bottleneck strength in the spatial dimensions
stride (int or tuple, optional) – Stride of the convolution. Default: 1
padding (int or tuple, optional) – Zero-padding added to both sides of the input. Default: 0
dilation (int or tuple, optional) – Spacing between kernel elements. Default: 1
repeats (int) – Number of convolutions to perform in the bottlenecked space
groups (int, optional) – Number of blocked connections from input channels to output channels. Default: 1
bias (bool, optional) – If
True, adds a learnable bias to the output. Default:Truepadding_mode (string, optional) –
'zeros','reflect','replicate'or'circular'. Default:'zeros'checkpoint (bool) –
Initializes internal Module state, shared by both nn.Module and ScriptModule.
-
forward(input)¶ - Parameters
input (torch.Tensor) –
- Return type
-
class
combustion.nn.Bottleneck3d(in_channels, out_channels, kernel_size, bn_depth=None, bn_spatial=None, stride=1, padding=None, dilation=1, repeats=1, groups=1, bias=False, padding_mode='zeros', checkpoint=False)[source]¶ Applies a 3D bottlnecked convolution over an input. Bottlnecked convolutions are detailed in the paper MobileNetV2: Inverted Residuals and Linear Bottlenecks .
Note
Nonlinearities are omitted for low dimensional subspaces as mentioned in section 6 of the paper MobileNetV2: Inverted Residuals and Linear Bottlenecks ,
- Parameters
in_channels (int) – Number of channels in the input image
out_channels (int) – Number of channels produced by the convolution
bn_depth (int) – Bottleneck strength in the channel dimension
bn_spatial (int) – Bottleneck strength in the spatial dimensions
stride (int or tuple, optional) – Stride of the convolution. Default: 1
padding (int or tuple, optional) – Zero-padding added to both sides of the input. Default: 0
dilation (int or tuple, optional) – Spacing between kernel elements. Default: 1
repeats (int) – Number of convolutions to perform in the bottlenecked space
groups (int, optional) – Number of blocked connections from input channels to output channels. Default: 1
bias (bool, optional) – If
True, adds a learnable bias to the output. Default:Truepadding_mode (string, optional) –
'zeros','reflect','replicate'or'circular'. Default:'zeros'checkpoint (bool) –
Initializes internal Module state, shared by both nn.Module and ScriptModule.
-
forward(input)¶ - Parameters
input (torch.Tensor) –
- Return type
-
class
combustion.nn.BottleneckFactorized2d(in_channels, out_channels, kernel_size, bn_depth=None, bn_spatial=None, stride=1, padding=None, dilation=1, repeats=1, groups=1, bias=False, padding_mode='zeros', checkpoint=False)[source]¶ Applies a 2D bottlnecked convolution over an input. Bottlnecked convolutions are detailed in the paper MobileNetV2: Inverted Residuals and Linear Bottlenecks . In the factorized case, spatial convolutions are performed along each spatial dimension separately.
Note
Nonlinearities are omitted for low dimensional subspaces as mentioned in section 6 of the paper MobileNetV2: Inverted Residuals and Linear Bottlenecks ,
- Parameters
in_channels (int) – Number of channels in the input image
out_channels (int) – Number of channels produced by the convolution
bn_depth (int) – Bottleneck strength in the channel dimension
bn_spatial (int) – Bottleneck strength in the spatial dimensions
stride (int or tuple, optional) – Stride of the convolution. Default: 1
padding (int or tuple, optional) – Zero-padding added to both sides of the input. Default: 0
dilation (int or tuple, optional) – Spacing between kernel elements. Default: 1
repeats (int) – Number of convolutions to perform in the bottlenecked space
groups (int, optional) – Number of blocked connections from input channels to output channels. Default: 1
bias (bool, optional) – If
True, adds a learnable bias to the output. Default:Truepadding_mode (string, optional) –
'zeros','reflect','replicate'or'circular'. Default:'zeros'checkpoint (bool) –
Initializes internal Module state, shared by both nn.Module and ScriptModule.
-
forward(input)¶ - Parameters
input (torch.Tensor) –
- Return type
-
class
combustion.nn.BottleneckFactorized3d(in_channels, out_channels, kernel_size, bn_depth=None, bn_spatial=None, stride=1, padding=None, dilation=1, repeats=1, groups=1, bias=False, padding_mode='zeros', checkpoint=False)[source]¶ Applies a 3D bottlnecked convolution over an input. Bottlnecked convolutions are detailed in the paper MobileNetV2: Inverted Residuals and Linear Bottlenecks . In the factorized case, spatial convolutions are performed along each spatial dimension separately.
Note
Nonlinearities are omitted for low dimensional subspaces as mentioned in section 6 of the paper MobileNetV2: Inverted Residuals and Linear Bottlenecks ,
- Parameters
in_channels (int) – Number of channels in the input image
out_channels (int) – Number of channels produced by the convolution
bn_depth (int) – Bottleneck strength in the channel dimension
bn_spatial (int) – Bottleneck strength in the spatial dimensions
stride (int or tuple, optional) – Stride of the convolution. Default: 1
padding (int or tuple, optional) – Zero-padding added to both sides of the input. Default: 0
dilation (int or tuple, optional) – Spacing between kernel elements. Default: 1
repeats (int) – Number of convolutions to perform in the bottlenecked space
groups (int, optional) – Number of blocked connections from input channels to output channels. Default: 1
bias (bool, optional) – If
True, adds a learnable bias to the output. Default:Truepadding_mode (string, optional) –
'zeros','reflect','replicate'or'circular'. Default:'zeros'checkpoint (bool) –
Initializes internal Module state, shared by both nn.Module and ScriptModule.
-
training¶
Dropout Layers¶
-
class
combustion.nn.DropConnect(ratio)[source]¶ Implements DropConnect as defined in Regularization of Neural Networks using DropConnect for use with convolutional layers.
- Parameters
ratio (float) – The ratio of elements to be dropped
- Shape
Input: \((N, C, d_1 \dots d_n)\) where \(d_1 \dots d_n\) is any number of additional dimensions.
Output: Same as input
Initializes internal Module state, shared by both nn.Module and ScriptModule.
Larger Modules¶
BiFPN¶
-
class
combustion.nn.BiFPN2d(num_channels, levels, kernel_size=3, stride=2, epsilon=0.0001, bn_momentum=0.9997, bn_epsilon=4e-05, activation=ReLU())[source]¶ A bi-directional feature pyramid network (BiFPN) used in the EfficientDet implementation (EfficientDet Scalable and Efficient Object Detection). The bi-directional FPN mixes features at different resolution, while also capturing (via learnable weights) that features at different resolutions can contribute unequally to the desired output.
Weights controlling the contribution of each FPN level are normalized using fast normalized fusion, which the authors note is more efficient than a softmax based fusion. It is ensured that for all weights, \(w_i > 0\) by applying ReLU to each weight.
The weight normalization is as follows
\[O = \sum_{i}\frac{w_i}{\epsilon + \sum_{j} w_j} \cdot I_i \]The structure of the block is as follows:

- Parameters
num_channels (int) – The number of channels in each feature pyramid level. All inputs \(P_i\) should have
num_channelschannels, and outputs \(P_i'\) will havenum_channelschannels.levels (int) – The number of levels in the feature pyramid. Must have
levels > 1.kernel_size (int or tuple of ints) – Choice of kernel size
stride (int or tuple of ints) – Controls the scaling used to upsample/downsample adjacent levels in the BiFPN. This stride is passed to
torch.nn.MaxPool2dandtorch.nn.Upsample.epsilon (float, optional) – Small value used for numerical stability when normalizing weights via fast normalized fusion. Default
1e-4.bn_momentum (float, optional) – Momentum for batch norm layers.
bn_epsilon (float, optional) – Epsilon for batch norm layers.
activation (
torch.nn.Module) – Activation function to use on convolution layers.
- Shape:
Inputs: List of Tensors of shape \((N, *C, *H, *W)\) where \(*C, *H, *W\) indicates variable channel/height/width at each level of downsapling.
Output: Same shape as input.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
-
BatchNorm¶ alias of
torch.nn.modules.batchnorm.BatchNorm2d
-
Conv¶ alias of
torch.nn.modules.conv.Conv2d
-
MaxPool¶ alias of
torch.nn.modules.pooling.MaxPool2d
-
static
Tuple(arg)¶
-
training¶
-
class
combustion.nn.BiFPN¶ Alias for
combustion.nn.BiFPN2dWarning
This class is deprecated. Please use
combustion.nn.BiFPN2dinstead
-
class
combustion.nn.BiFPN1d¶ 1d variant of
combustion.nn.BiFPN2d
-
class
combustion.nn.BiFPN3d¶ 3d variant of
combustion.nn.BiFPN2d
MobileNetV3 Inverted Bottleneck¶
-
class
combustion.nn.MobileNetConvBlock2d(input_filters, output_filters, kernel_size, stride=1, bn_momentum=0.1, bn_epsilon=1e-05, activation=HardSwish(), squeeze_excite_ratio=1, expand_ratio=1, use_skipconn=True, drop_connect_rate=0.0, padding_mode='zeros')[source]¶ Implementation of the MobileNet inverted bottleneck block as described in Searching for MobileNetV3. This implementation includes enhancements from MobileNetV3, such as the hard swish activation function (via
combustion.nn.HardSwish) and squeeze/excitation layers (viacombustion.nn.SqueezeExcite2d).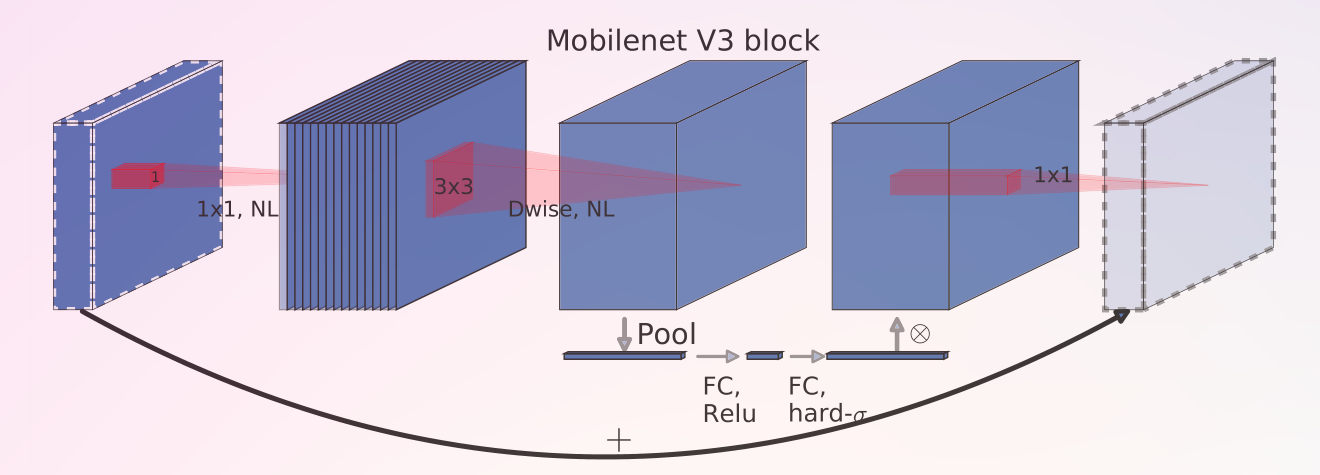
See
MobileNetConvBlock1dandMobileNetConvBlock3dfor 1d / 3d variants.- Parameters
input_filters (int) – The number of input channels, \(C_i\) See
torch.nn.Conv2dfor more details.output_filters (int) – Number of output channels, \(C_o\) See
torch.nn.Conv2dfor more details.kernel_size (int or tuple of ints) – Kernel size for the depthwise (spatial) convolutions See
torch.nn.Conv2dfor more details.stride (int or tuple of ints) – Stride for the depthwise (spatial) convolutions. See
torch.nn.Conv2dfor more details.bn_momentum (float) – Momentum for batch normalization layers. See
torch.nn.BatchNorm2dfor more details.bn_epsilon (float) – Epsilon for batch normalization layers. See
torch.nn.BatchNorm2dfor more details.activation (
torch.nn.Module) – Choice of activation function. Typically this will either be ReLU or Hard Swish depending on where the block is located in the network.squeeze_excite_ratio (float) – Ratio by which channels will be squeezed in the squeeze/excitation layer. See
combustion.nn.SqueezeExcite2dfor more details.expand_ratio (float) – Ratio by which channels will be expanded in the inverted bottleneck.
use_skipconn (bool) – Whether or not to use skip connections.
drop_connect_rate (float) – Drop probability for DropConnect layer. Defaults to
0.0, i.e. no DropConnect layer will be used.padding_mode (str) – Padding mode to use for all non-pointwise convolution layers. See
torch.nn.Conv2dfor more details.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
-
classmethod
from_config(config)¶ Constructs a MobileNetConvBlock using a MobileNetBlockConfig dataclass.
- Parameters
config (
combustion.nn.MobileNetBlockConfig) – Configuration for the block to construct- Return type
Union[torch.nn.modules.container.Sequential, combustion.nn.modules.mobilenet._MobileNetConvBlockNd]
-
class
combustion.nn.MobileNetBlockConfig(input_filters, output_filters, kernel_size, stride=1, bn_momentum=0.1, bn_epsilon=1e-05, squeeze_excite_ratio=1.0, expand_ratio=1.0, use_skipconn=True, drop_connect_rate=0.0, padding_mode='zeros', num_repeats=1)[source]¶ Data class that groups parameters for MobileNet inverted bottleneck blocks (
MobileNetConvBlock1d,MobileNetConvBlock2d,MobileNetConvBlock4d).- Parameters
input_filters (int) – The number of input channels, \(C_i\) See
torch.nn.Conv2dfor more details.output_filters (int) – Number of output channels, \(C_o\) See
torch.nn.Conv2dfor more details.kernel_size (int or tuple of ints) – Kernel size for the depthwise (spatial) convolutions See
torch.nn.Conv2dfor more details.stride (int or tuple of ints) – Stride for the depthwise (spatial) convolutions. See
torch.nn.Conv2dfor more details.bn_momentum (float) – Momentum for batch normalization layers. See
torch.nn.BatchNorm2dfor more details.bn_epsilon (float) – Epsilon for batch normalization layers. See
torch.nn.BatchNorm2dfor more details.activation (
torch.nn.Module) – Choice of activation function. Typically this will either be ReLU or Hard Swish depending on where the block is located in the network.squeeze_excite_ratio (float) – Ratio by which channels will be squeezed in the squeeze/excitation layer. See
combustion.nn.SqueezeExcite2dfor more details.expand_ratio (float) – Ratio by which channels will be expanded in the inverted bottleneck.
use_skipconn (bool) – Whether or not to use skip connections.
drop_connect_rate (float) – Drop probability for DropConnect layer. Defaults to
0.0, i.e. no DropConnect layer will be used.padding_mode (str) – Padding mode to use for all non-pointwise convolution layers. See
torch.nn.Conv2dfor more details.num_repeats (int) –
- Return type
-
class
combustion.nn.MobileNetConvBlock1d¶ 1d version of
combustion.nn.MobileNetConvBlock2d.
-
class
combustion.nn.MobileNetConvBlock3d¶ 3d version of
combustion.nn.MobileNetConvBlock2d.
Squeeze and Excitation¶
-
class
combustion.nn.SqueezeExcite1d(in_channels, squeeze_ratio, out_channels=None, first_activation=ReLU(), second_activation=HardSigmoid())[source]¶ Implements the 1d squeeze and excitation block described in Squeeze-and-Excitation Networks, with modifications described in Searching for MobileNetV3. Squeeze and excitation layers aid in capturing global information embeddings and channel-wise dependencies.
Channels after the squeeze will be given by
\[C_\text{squeeze} = \max\bigg(1, \Big\lfloor\frac{\text{in\_channels}}{\text{squeeze\_ratio}}\Big\rfloor\bigg) \]- Parameters
in_channels (int) – Number of input channels \(C_i\).
squeeze_ratio (float) – Ratio by which channels will be reduced when squeezing.
out_channels (optional, int) – Number of output channels \(C_o\). Defaults to
in_channels.first_activation (
torch.nn.Module) – Activation to be applied following the squeeze step. Defaults totorch.nn.ReLU.second_activation (
torch.nn.Module) – Activation to be applied following the excitation step. Defaults tocombustion.nn.HardSwish.
- Shape
Input: \((N, C_i, L)\) where \(N\) is the batch dimension and \(C_i\) is the channel dimension.
Output: \((N, C_o, 1)\).
Initializes internal Module state, shared by both nn.Module and ScriptModule.
-
class
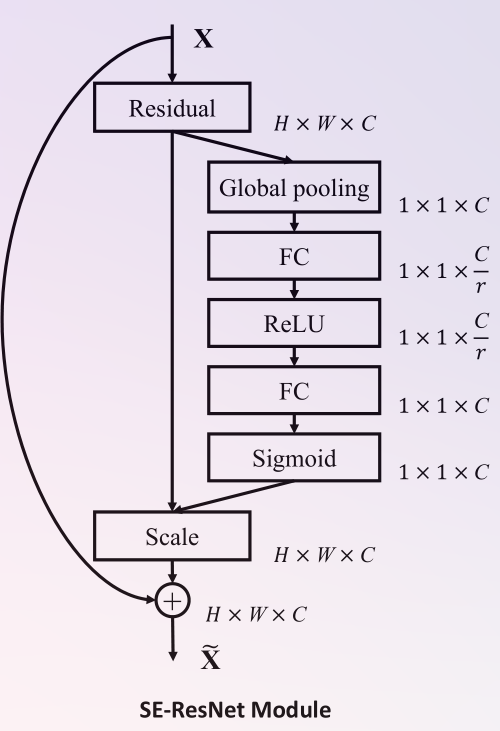
combustion.nn.SqueezeExcite2d(in_channels, squeeze_ratio, out_channels=None, first_activation=ReLU(), second_activation=HardSigmoid())[source]¶ Implements the 2d squeeze and excitation block described in Squeeze-and-Excitation Networks, with modifications described in Searching for MobileNetV3. Squeeze and excitation layers aid in capturing global information embeddings and channel-wise dependencies.
Channels after the squeeze will be given by
\[C_\text{squeeze} = \max\bigg(1, \Big\lfloor\frac{\text{in\_channels}}{\text{squeeze\_ratio}}\Big\rfloor\bigg) \]Diagram of the original squeeze/excitation layer
- Parameters
in_channels (int) – Number of input channels \(C_i\).
squeeze_ratio (float) – Ratio by which channels will be reduced when squeezing.
out_channels (optional, int) – Number of output channels \(C_o\). Defaults to
in_channels.first_activation (
torch.nn.Module) – Activation to be applied following the squeeze step. Defaults totorch.nn.ReLU.second_activation (
torch.nn.Module) – Activation to be applied following the excitation step. Defaults tocombustion.nn.HardSwish.
- Shape
Input: \((N, C_i, H, W)\) where \(N\) is the batch dimension and \(C_i\) is the channel dimension.
Output: \((N, C_o, 1, 1)\).
Initializes internal Module state, shared by both nn.Module and ScriptModule.
-
class
combustion.nn.SqueezeExcite3d(in_channels, squeeze_ratio, out_channels=None, first_activation=ReLU(), second_activation=HardSigmoid())[source]¶ Implements the 3d squeeze and excitation block described in Squeeze-and-Excitation Networks, with modifications described in Searching for MobileNetV3. Squeeze and excitation layers aid in capturing global information embeddings and channel-wise dependencies.
Channels after the squeeze will be given by
\[C_\text{squeeze} = \max\bigg(1, \Big\lfloor\frac{\text{in\_channels}}{\text{squeeze\_ratio}}\Big\rfloor\bigg) \]- Parameters
in_channels (int) – Number of input channels \(C_i\).
squeeze_ratio (float) – Ratio by which channels will be reduced when squeezing.
out_channels (optional, int) – Number of output channels \(C_o\). Defaults to
in_channels.first_activation (
torch.nn.Module) – Activation to be applied following the squeeze step. Defaults totorch.nn.ReLU.second_activation (
torch.nn.Module) – Activation to be applied following the excitation step. Defaults tocombustion.nn.HardSwish.
- Shape
Input: \((N, C_i, D, H, W)\) where \(N\) is the batch dimension and \(C_i\) is the channel dimension.
Output: \((N, C_o, 1, 1, 1)\).
Initializes internal Module state, shared by both nn.Module and ScriptModule.
Reduced Atrous Spatial Pyramid Pooling (R-ASPP Lite)¶
-
class
combustion.nn.RASPPLite2d(input_filters, residual_filters, output_filters, num_classes, pool_kernel=42, pool_stride=18, dilation=1, sigmoid=Sigmoid(), relu=ReLU(), bn_momentum=0.1, bn_epsilon=1e-05, final_upsample=1)[source]¶ Implements the a lite version of the reduced atrous spatial pyramid pooling module (R-ASPP Lite) described in Searching for MobileNetV3. This is a semantic segmentation head.
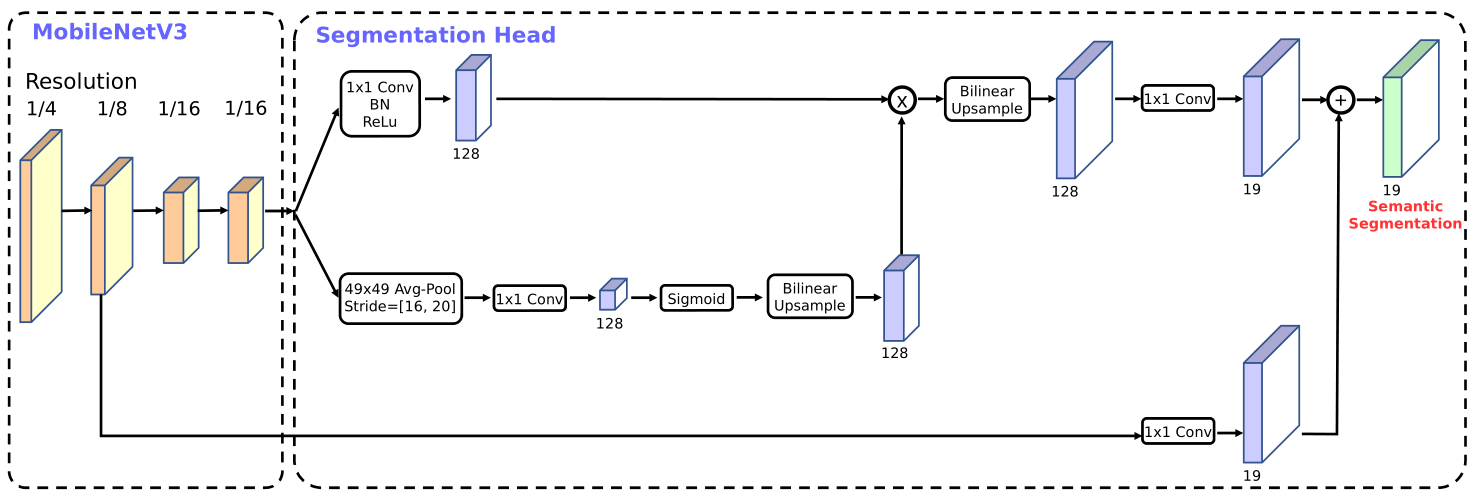
- Parameters
input_filters (int) – Number of input channels along the main pathway
residual_filters (int) – Number of input channels along the residual pathway
output_filters (int) – Number of channels in the middle of the segmentation head.
num_classes (int) – Number of classes for semantic segmentation
pool_kernel (int or tuple of ints) – Size of the average pooling kernel
pool_stride (int or tuple of ints) – Stride of the average pooling kernel
dilation (int or tuple of ints) – Dilation of the atrous convolution. Defaults to
1, meaning no atrous convolution.sigmoid (
torch.nn.Module) – Activation function to use along the pooled pathwayrelu (
torch.nn.Module) – Activation function to use along the main convolutional pathwaybn_momentum (float) – Batch norm momentum
bn_epsilon (float) – Batch norm epsilon
final_upsample (int) – An optional amount of additional to be applied via transposed convolutions. It is expected that additional upsampling is a power of two.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
-
class
combustion.nn.RASPPLite1d¶ 1d version of
combustion.nn.RASPPLite2d.
-
class
combustion.nn.RASPPLite3d¶ 3d version of
combustion.nn.RASPPLite2d.
Loss Functions¶
-
class
combustion.nn.CenterNetLoss(gamma=2.0, pos_weight=4.0, label_smoothing=None, reduction='mean', smooth=True)[source]¶ The loss function used for CenterNet and similar networks, as described in the paper Objects as Points.
- Parameters
gamma (float) – The focusing parameter \(\gamma\). Must be non-negative. Note that this parameter is referred to as \(\alpha\) in Objects as Points and \(\gamma\) in the focal loss literature.
pos_weight (float, optional) – The positive weight coefficient \(\alpha\) to use on the positive examples. Must be non-negative. Note that this parameter is referred to as \(\beta\) in Objects as Points and \(\alpha\) in the focal loss literature.
label_smoothing (float, optional) – Float in [0, 1]. When 0, no smoothing occurs. When positive, the binary ground truth labels are clamped to \([p, 1-p]\).
reduction (str, optional) – Specifies the reduction to apply to the output:
'none'|'mean'|'sum'.'none': no reduction will be applied,'mean': the sum of the output will be divided by the number of elements in the output,'sum': the output will be summed. Default:'mean'smooth (bool, optional) – If true, use a smooth L1 loss to compute regression losses. Default
True.
- Returns
Tuple of tensors giving the classification and regression losses respectively. If
reduction='none'the output tensors will be the same shape as inputs, otherwise scalar tensors will be returned.
- Shape
Inputs: \((*, N+4, H, W)\) where \(*\) means an optional batch dimension and \(N\) is the number of classes. Indices \(N+1, N+2\) should give the \(x, y\) regression offsets, while indices \(N+3, N+4\) should give the height and width regressions.
Targets: Same shape as input.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
Focal Loss¶
-
combustion.nn.focal_loss_with_logits(input, target, gamma, pos_weight=None, label_smoothing=None, reduction='mean', normalize=False)[source]¶ Computes the Focal Loss between input and target. See
FocalLossWithLogitsfor more details- Parameters
input (torch.Tensor) – The predicted values.
target (torch.Tensor) – The target values.
gamma (float) – The focusing parameter \(\gamma\). Must be non-negative.
pos_weight (float, optional) – The positive weight coefficient \(\alpha\) to use on the positive examples. Must be non-negative.
label_smoothing (float, optional) – Float in [0, 1]. When 0, no smoothing occurs. When positive, the binary ground truth labels are clamped to \([p, 1-p]\).
reduction (str, optional) – Specifies the reduction to apply to the output:
'none'|'mean'|'sum'.'none': no reduction will be applied,'mean': the sum of the output will be divided by the number of elements in the output,'sum': the output will be summed. Default:'mean'normalize (bool, optional) – If given, output loss will be divided by the number of positive elements in
target.
-
combustion.nn.focal_loss(input, target, gamma, pos_weight=None, label_smoothing=None, reduction='mean', normalize=False)[source]¶ Computes the Focal Loss between input and target. See
FocalLossfor more details- Parameters
input (torch.Tensor) – The predicted values on the interval \([0, 1]\).
target (torch.Tensor) – The target values on the interval \([0, \)]`.
gamma (float) – The focusing parameter \(\gamma\). Must be non-negative.
pos_weight (float, optional) – The positive weight coefficient \(\alpha\) to use on the positive examples. Must be non-negative.
label_smoothing (float, optional) – Float in [0, 1]. When 0, no smoothing occurs. When positive, the binary ground truth labels are clamped to \([p, 1-p]\).
reduction (str, optional) – Specifies the reduction to apply to the output:
'none'|'mean'|'sum'.'none': no reduction will be applied,'mean': the sum of the output will be divided by the number of elements in the output,'sum': the output will be summed. Default:'mean'normalize (bool, optional) – If given, output loss will be divided by the number of positive elements in
target.
-
class
combustion.nn.FocalLoss(gamma, pos_weight=None, label_smoothing=None, reduction='mean', normalize=False)[source]¶ Creates a criterion that measures the Focal Loss between the target and the output. Focal loss is described in the paper Focal Loss For Dense Object Detection.
- Parameters
gamma (float) – The focusing parameter \(\gamma\). Must be non-negative.
pos_weight (float, optional) – The positive weight coefficient \(\alpha\) to use on the positive examples. Must be non-negative.
label_smoothing (float, optional) – Float in [0, 1]. When 0, no smoothing occurs. When positive, the binary ground truth labels are clamped to \([p, 1-p]\).
reduction (str, optional) – Specifies the reduction to apply to the output:
'none'|'mean'|'sum'.'none': no reduction will be applied,'mean': the sum of the output will be divided by the number of elements in the output,'sum': the output will be summed. Default:'mean'normalize (bool, optional) – If given, output loss will be divided by the number of positive elements in
target.
- Shape:
Input: \((N, *)\) where \(*\) means, any number of additional dimensions
Target: \((N, *)\), same shape as the input
Output: scalar. If
reductionis'none', then \((N, *)\), same shape as input.
Examples:
>>> loss = FocalLoss(gamma=1.0, pos_weight=0.8) >>> pred = torch.rand(10, 10, requires_grad=True) >>> target = torch.rand(10, 10).round() >>> output = loss(pred, target)
Initializes internal Module state, shared by both nn.Module and ScriptModule.
-
class
combustion.nn.FocalLossWithLogits(gamma, pos_weight=None, label_smoothing=None, reduction='mean', normalize=False)[source]¶ Creates a criterion that measures the Focal Loss between the target and the output. Focal loss is described in the paper Focal Loss For Dense Object Detection. Inputs are expected to be logits (i.e. not already scaled to the interval \([0, 1]\) through a sigmoid or softmax). This computation on logits is more numerically stable and efficient for reverse mode auto-differentiation and should be preferred for that use case.
- Parameters
gamma (float) – The focusing parameter \(\gamma\). Must be non-negative.
pos_weight (float, optional) – The positive weight coefficient \(\alpha\) to use on the positive examples. Must be non-negative.
label_smoothing (float, optional) – Float in [0, 1]. When 0, no smoothing occurs. When positive, the binary ground truth labels are clamped to \([p, 1-p]\).
reduction (str, optional) – Specifies the reduction to apply to the output:
'none'|'mean'|'sum'.'none': no reduction will be applied,'mean': the sum of the output will be divided by the number of elements in the output,'sum': the output will be summed. Default:'mean'normalize (bool, optional) – If given, output loss will be divided by the number of positive elements in
target.
- Shape:
Input: \((N, *)\) where \(*\) means, any number of additional dimensions
Target: \((N, *)\), same shape as the input
Output: scalar. If
reductionis'none', then \((N, *)\), same shape as input.
Examples:
>>> loss = FocalLoss(gamma=1.0, pos_weight=0.8) >>> pred = torch.rand(10, 10, requires_grad=True) >>> target = torch.rand(10, 10).round() >>> output = loss(pred, target)
Initializes internal Module state, shared by both nn.Module and ScriptModule.
Utilities¶
-
class
combustion.nn.Standardize(dims, epsilon=1e-09, unbiased=True)[source]¶ Standardizes an input tensor to zero mean unit variance along one or more dimensions. Mean and variance will be computed over the selected dimensions, and the resultant tensor will be computed as
\[x_o = \frac{x_i - \mu}{\max(\sigma^2, \epsilon)} \]- Parameters
dims (int or tuple of ints) – The dimension(s) to standardize over
epsilon (float, optional) – Lower bound on variance
unbiased (bool, optional) – Whether or not to used unbiased estimation in variance calculation. See
torch.var_mean()for more details.
- Shape:
Inputs: Tensor of shape \((*)\) where \(*\) indicates an arbitrary number of dimensions.
Output: Same shape as input.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
-
training¶
