combustion.models¶
Model implementations
combustion.models
Convolutional Models¶
EfficientNet¶
-
class
combustion.models.EfficientNet2d(block_configs, width_coeff=1.0, depth_coeff=1.0, width_divisor=8.0, min_width=None, stem=None, head=None, checkpoint=False)[source]¶ Implementation of EfficientNet as described in the EfficientNet paper. EfficientNet defines a family of models that are built using convolutional blocks that are parameterized such that width, depth, and spatial resolution can be easily scaled up or down. The authors of EfficientNet note that scaling each of these dimensions simultaneously is advantageous.
Let the depth, width, and resolution of the model be denoted by \(d, w, r\) respectively. EfficientNet defines a compound scaling factor \(\phi\) such that
\[d = \alpha^\phi \\ w = \beta^\phi \\ r = \gamma^\phi \]where
\[\alpha * \beta^2 * \gamma^2 \approx 2 \]The parameters \(\alpha,\beta,\gamma\) are experimentally determined and describe how finite computational resources should be distributed amongst depth, width, and resolution scaling. The parameter \(\phi\) is a user controllable compound scaling coefficient such that for a new \(\phi\), FLOPS will increase by approximately \(2^\phi\).
The authors of EfficientNet selected the following scaling parameters:
\[\alpha = 1.2 \\ \beta = 1.1 \\ \gamma = 1.15 \]Note
Currently, DropConnect ratios are not scaled based on depth of the given block. This is a deviation from the true EfficientNet implementation.
- Parameters
block_configs (list of
combustion.nn.MobileNetBlockConfig) – Configs for each of thecombustion.nn.MobileNetConvBlock2dblocks used in the model.width_coeff (float) – The width scaling coefficient. Increasing this increases the width of the model.
depth_coeff (float) – The depth scaling coefficient. Increasing this increases the depth of the model.
width_divisor (float) – Used in calculating number of filters under width scaling. Filters at each block will be a multiple of
width_divisor.min_width (int) – The minimum width of the model at any block
stem (
torch.nn.Module) – An optional stem to use for the model. The default stem is a single 3x3/2 conolution that expects 3 input channels.head (
torch.nn.Module) – An optional head to use for the model. By default, no head will be used andforwardwill return a list of tensors containing extracted features.checkpoint (bool) – If true, use checkpointing on each block in the backbone. Checkpointing saves memory at the cost of added compute. See
torch.utils.checkpoint.checkpoint()for more details.
- Shapes
Input: \((N, C, H, W)\)
Output: List of tensors of shape \((N, C, H', W')\), where height and width vary depending on the amount of downsampling for that feature map.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
-
extract_features(inputs, return_all=False)¶ Runs the EfficientNet stem and body to extract features, returning a list of tensors representing features extracted from each block.
- Parameters
inputs (
torch.Tensor) – Model inputsreturn_all (bool) – By default, only features extracted from blocks with non-unit stride will be returned. If
return_all=True, return features extracted from every block group in the model.
- Return type
List[torch.Tensor]
-
forward(inputs, use_all_features=False)¶ Runs the entire EfficientNet model, including stem, body, and head. If no head was supplied, the output of
extract_features()will be returned. Otherwise, the output of the given head will be returned.Note
The returned output will always be a list of tensors. If a custom head is given and it returns a single tensor, that tensor will be wrapped in a list before being returned.
- Parameters
inputs (
torch.Tensor) – Model inputsreturn_all (bool) – By default, only features extracted from blocks with non-unit stride will be returned. If
return_all=True, return features extracted from every block group in the model.use_all_features (bool) –
- Return type
List[torch.Tensor]
-
classmethod
from_predefined(compound_coeff, **kwargs)¶ Creates an EfficientNet model using one of the parameterizations defined in the EfficientNet paper.
- Parameters
compound_coeff (int) – Compound scaling parameter \(\phi\). For example, to construct EfficientNet-B0, set
compound_coeff=0.**kwargs – Additional parameters/overrides for model constructor.
- Return type
combustion.models.efficientnet._EfficientNet
-
class
combustion.models.EfficientNet1d¶ 1d variant of
combustion.models.EfficientNet2d
-
class
combustion.models.EfficientNet3d¶ 3d variant of
combustion.models.EfficientNet2d
EfficientDet¶
-
class
combustion.models.EfficientDet2d(block_configs, fpn_levels=[3, 5, 7, 8, 9], fpn_filters=64, fpn_repeats=3, width_coeff=1.0, depth_coeff=1.0, width_divisor=8.0, min_width=None, stem=None, head=None, fpn_kwargs={})[source]¶ Implementation of EfficientDet as described in the EfficientDet paper. EfficientDet is built on an EfficientNet backbone (see
combustion.models.EfficientNet2dfor details). EfficientDet adds a bidirectional feature pyramid network (seecombustion.nn.BiFPN2d), which mixes information across the various feature maps produced by the EfficientNet backbone.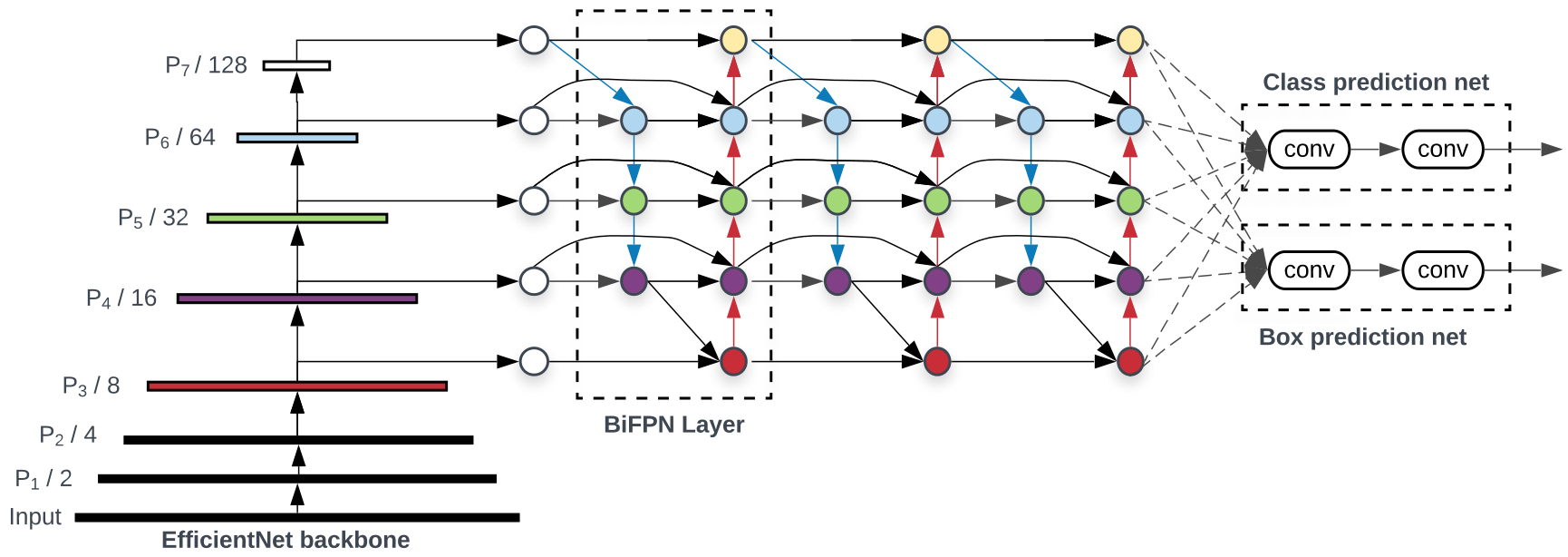
The authors of EfficientDet used the default EfficientNet scaling parameters for the backbone:
\[\alpha = 1.2 \\ \beta = 1.1 \\ \gamma = 1.15 \]The BiFPN was scaled as follows:
\[W_\text{bifpn} = 64 \cdot \big(1.35^\phi\big) \\ D_\text{bifpn} = 3 + \phi \]In the original EfficientDet implementation, the authors extract feature maps from levels 3, 5, and 7 of the backbone. Two additional coarse levels are created by performing additional strided convolutions to the final level in the backbone, for a total of 5 levels in the BiFPN.
Note
Currently, DropConnect ratios are not scaled based on depth of the given block. This is a deviation from the true EfficientNet implementation.
- Parameters
block_configs (list of
combustion.nn.MobileNetBlockConfig) – Configs for each of thecombustion.nn.MobileNetConvBlock2dblocks used in the model.fpn_levels (list of ints) – Indicies of EfficientNet feature levels to include in the BiFPN, starting at index 1. Values in
fpn_levelsgreater than the total number of blocks in the backbone denote levels that should be created by applying additional strided convolutions to the final level in the backbone.fpn_filters (int) – Number of filters to use for the BiFPN. The filter count given here should be the desired number of filters after width scaling.
fpn_repeats (int) – Number of repeats to use for the BiFPN. The repeat count given here should be the desired number of repeats after depth scaling.
width_coeff (float) – The width scaling coefficient. Increasing this increases the width of the model.
depth_coeff (float) – The depth scaling coefficient. Increasing this increases the depth of the model.
width_divisor (float) – Used in calculating number of filters under width scaling. Filters at each block will be a multiple of
width_divisor.min_width (int) – The minimum width of the model at any block
stem (
torch.nn.Module) – An optional stem to use for the model. The default stem is a single 3x3/2 conolution that expects 3 input channels.head (
torch.nn.Module) – An optional head to use for the model. By default, no head will be used andforwardwill return a list of tensors containing extracted features.fpn_kwargs (dict) – Keyword args to be passed to all
combustion.nn.BiFPN2dlayers.
- Shapes
Input: \((N, C, H, W)\)
Output: List of tensors of shape \((N, C, H', W')\), where height and width vary depending on the amount of downsampling for that feature map.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
-
extract_features(inputs)¶ Runs the EfficientDet stem and body to extract features, returning a list of tensors representing features extracted from each block.
- Parameters
inputs (
torch.Tensor) – Model inputs- Return type
List[torch.Tensor]
-
forward(inputs)¶ Runs the entire EfficientDet model, including stem, body, and head. If no head was supplied, the output of
extract_features()will be returned. Otherwise, the output of the given head will be returned.Note
The returned output will always be a list of tensors. If a custom head is given and it returns a single tensor, that tensor will be wrapped in a list before being returned.
- Parameters
inputs (
torch.Tensor) – Model inputs- Return type
List[torch.Tensor]
-
classmethod
from_predefined(compound_coeff, **kwargs)¶ Creates an EfficientDet model using one of the parameterizations defined in the EfficientDet paper.
- Parameters
compound_coeff (int) – Compound scaling parameter \(\phi\). For example, to construct EfficientDet-D0, set
compound_coeff=0.**kwargs – Additional parameters/overrides for model constructor.
- Return type
combustion.models.efficientdet._EfficientDet
-
class
combustion.models.EfficientDet3d¶ 3d variant of
combustion.models.EfficientDet2d
-
class
combustion.models.EfficientDet1d¶ 1d variant of
combustion.models.EfficientDet2d
